Simulating Covid-19: Part 2
In a previous post, I presented a “dots in a box” model of the spread of a virus. In this post, I use it to compare the economic and social cost of two policies that are equally effective at containing the virus.
What the simulations show is that if we use a test to determine who gets put into isolation the fraction of the population that needs to be confined and isolated is dramatically smaller. These benefits are available even with an imperfect test and without doing any contact tracing. It does take frequent testing, with each person getting retested roughly every two weeks.
Here are two plots that show the key result from the simulations. Each colored line represents one run from the 50 simulations. The black lines shows the average across all 50.
Isolating Based on Test Results
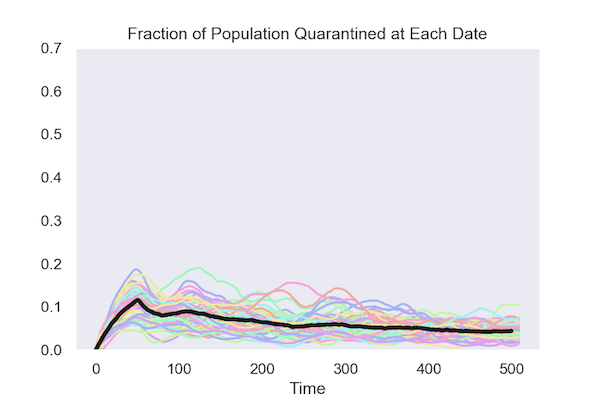
Isolating at Random
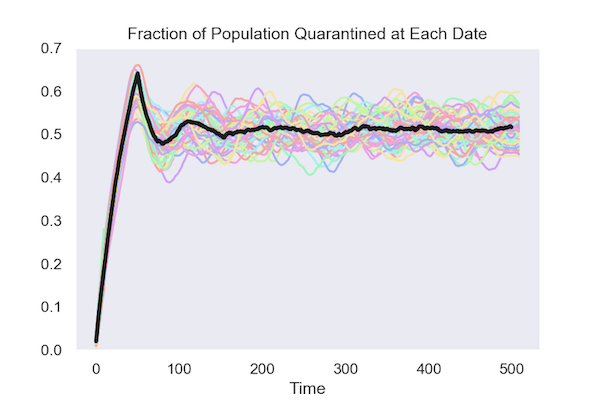
This comparison shows that isolation based on test results requires much less disruption to normal patterns of social interaction. An economy can survive with 10% of the population insolation. It can’t survive when 50% of the population is in isolation.
It is not hard to see why targeting the isolation based on test results reduces the total number of people in isolation. What matters for controlling the infection is how many infectious people it isolates. If people are isolated at random, you have to isolate a lot more to get the same number of people who are infectious.
Details
As before, the model has three types of markers that move around in a box:
- Blue inverted triangles, who are vulnerable to catching the virus.
- Red circles, who are infectious.
- Purple squares, who were infectious before but have recovered and now can neither catch nor transmit the virus.
To illustrate the effect of isolation, the model introduces a fourth symbol – a hollow orange box. Individuals that have been put in a box can’t move. Other individuals can’t get close because they “bounce” off its walls. After some time has elapsed, the box goes away and the individual is once more free to move around and interact with others.
The only difference between the two policies is how dots are selected for isolation.
Under the frequent testing policy, 7% of the population is randomly selected for testing each day. Over the 500 days illustrated in the plots and the animation, this means that the average person is tested about 30 times in 500 days – roughly once very two weeks.
Those that test positive are isolated. Because the test generates both false positives, some vulnerable individuals (blue inverted triangles) and some immune individuals (purple squares) are put in a box. (The test is far from perfect. I assume a 20% false negative rate and a 1% false positive rate.)
Under the random isolation policy, a fixed fraction of the population is randomly selected for isolation each day. I found the number that needed to be isolated by starting with a low value and increasing it until the random policy is on average, as effective at containing the spread of the virus as the targeted policy that relies on the tests.
Animations
It is easier to see the details of the model if you watch each of the videos separately in full screen mode.
Isolating Based on Test Results
Isolating at Random
There are two obvious differences between these animations. Under the targeted policy that uses a test to decide who gets put into quarantine:
- A larger fraction of the individuals in isolation are the infectious ones signaled by the red dot.
- Many fewer people are isolated.
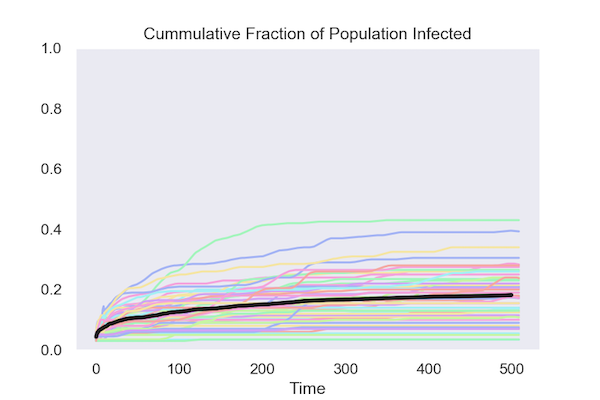
Simulated data for 50 runs of each model
Both policies keep the cumulative fraction of the population that is infected below 20%.
Isolating Based on Test Results
Isolating at Random
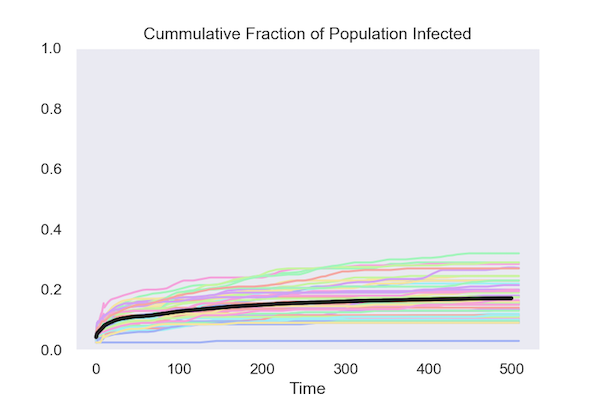
Under both policies, the fraction of the population that is infected (known as the attack rate) peaks early and declines, in most runs reaching zero.
Isolating Based on Test Results
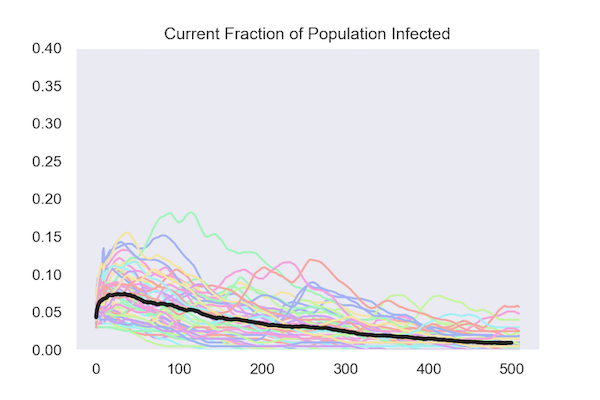
Isolating at Random
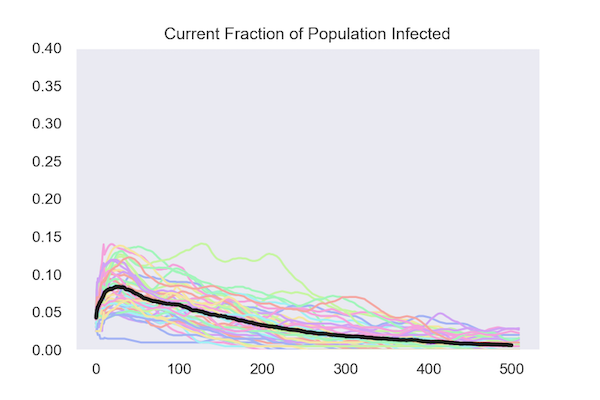
Technical Notes:
-
This toy model is NOT CALIBRATED to real data. All the numbers and results are indicative, not predictive about the true behavior of the spread of the virus. You should not take any number that emerges from the model as being something you can rely on. What the model does allow is a qualitative comparison of different policies. Moreover, the animation which shows the state of the model at each date or time slice, may help some people develop some intuition about common features in this class of models.
-
With those caveats, here are some of the specifics. Under the targeted policy, a random selection of about 7% of the population is tested each day. The test has a 20% false negative rate; i.e. 20% of the people who are actually infectious will get a negative test result. This can arise because of bad swab or a very low level of virus in the early stage of infection. The test is also assumed to have a 1% false positive rate; that is, 1% of people who are not infectious will nevertheless test positive. Although 7% of the population is tested each day, a small fraction test positive and go into quarantine.
-
Under the random isolation policy, a random selection from the population is assigned to isolation each day. They stay in isolation for a fixed length of time. To achieve the same goal – a cumulative infection rate less than 20% – this random isolation policy has to put a lot more people into quarantine, 3% of the population each day. I found this 3% rate by increasing it until the random isolation policy succeeded in keeping the cumulative infection rate under the same value, 20%, that the targeted policy that bases isolation on test results achieves. Given the time that someone has to spend in isolation, this means an average isolation rate in the population of about 50%.
-
I will make the Python behind these simulations available in a Jupyter notebook as soon as I have a chance to clean it up and document it.